SQL ... and now GQL
By Alastair Green (Lead, Query Languages Standards and Research Group at Neo4j) | 12 September 2019
This is a reproduction of the article originally posted here.
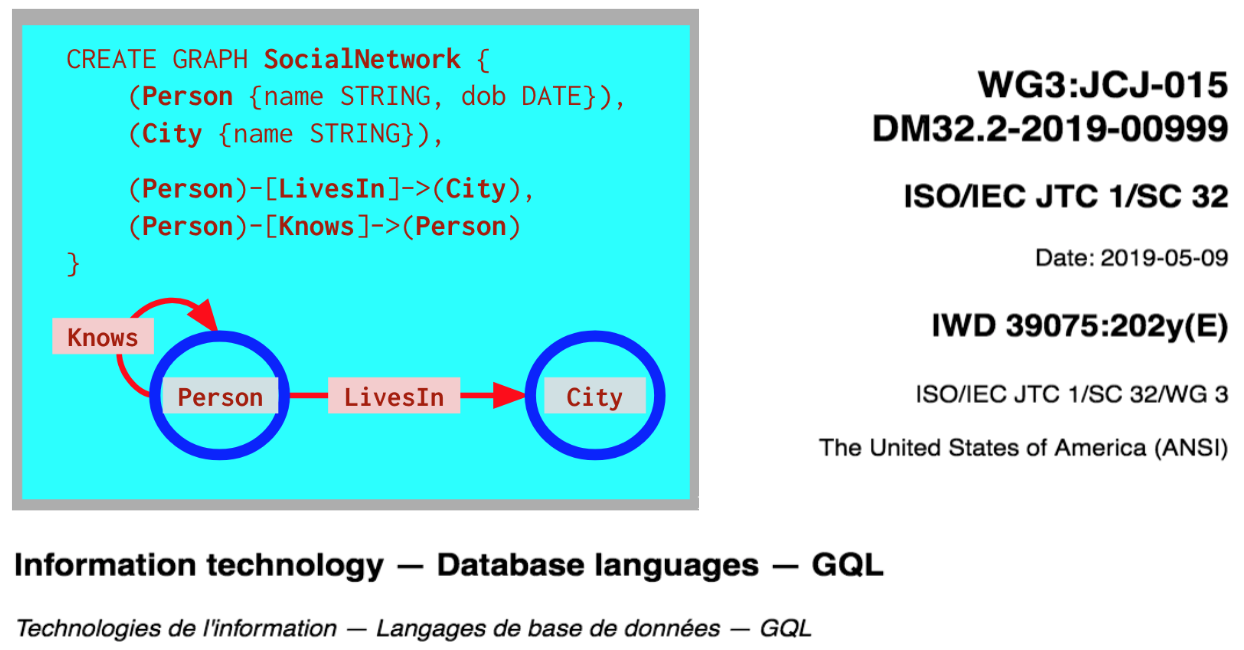
A standard query language for property graphs
It’s official. In June national standards bodies around the world belonging to ISO/IEC’s Joint Technical Committee 1 (which is responsible for IT standards) started voting on the GQL project proposal. Earlier this week, the ballot closed and the proposal passed, with seven countries putting experts forward to work on the four-year project.
GQL stands for “Graph Query Language”. The new language will be developed and maintained by the same international working group that looks after the SQL standard. GQL draws heavily on existing languages.
The main inspirations have been Cypher (now with over ten implementations, including six commercial products), Oracle’s PGQL and SQL itself, as well as new extensions for read-only property graph querying to SQL. Tigergraph’s GSQL, although coming from a stylistically different starting point than the other inputs, is another noteworthy contribution, whose authors have shown strong commitment to the GQL project.
It’s well over thirty years since the SQL project started, initially as an ANSI standard: GQL is the first ISO/IEC international standard database languages project after SQL. Ten countries voted for the new project: China, Korea, Sweden, the U.S., Germany, the U.K., the Netherlands, Denmark, Kazakhstan, Canada and Finland. Five abstained on grounds of lack of expertise to judge or comment on the proposal. The diagram below shows the countries who have not only voted “Yes”, but also pledged expert participation.
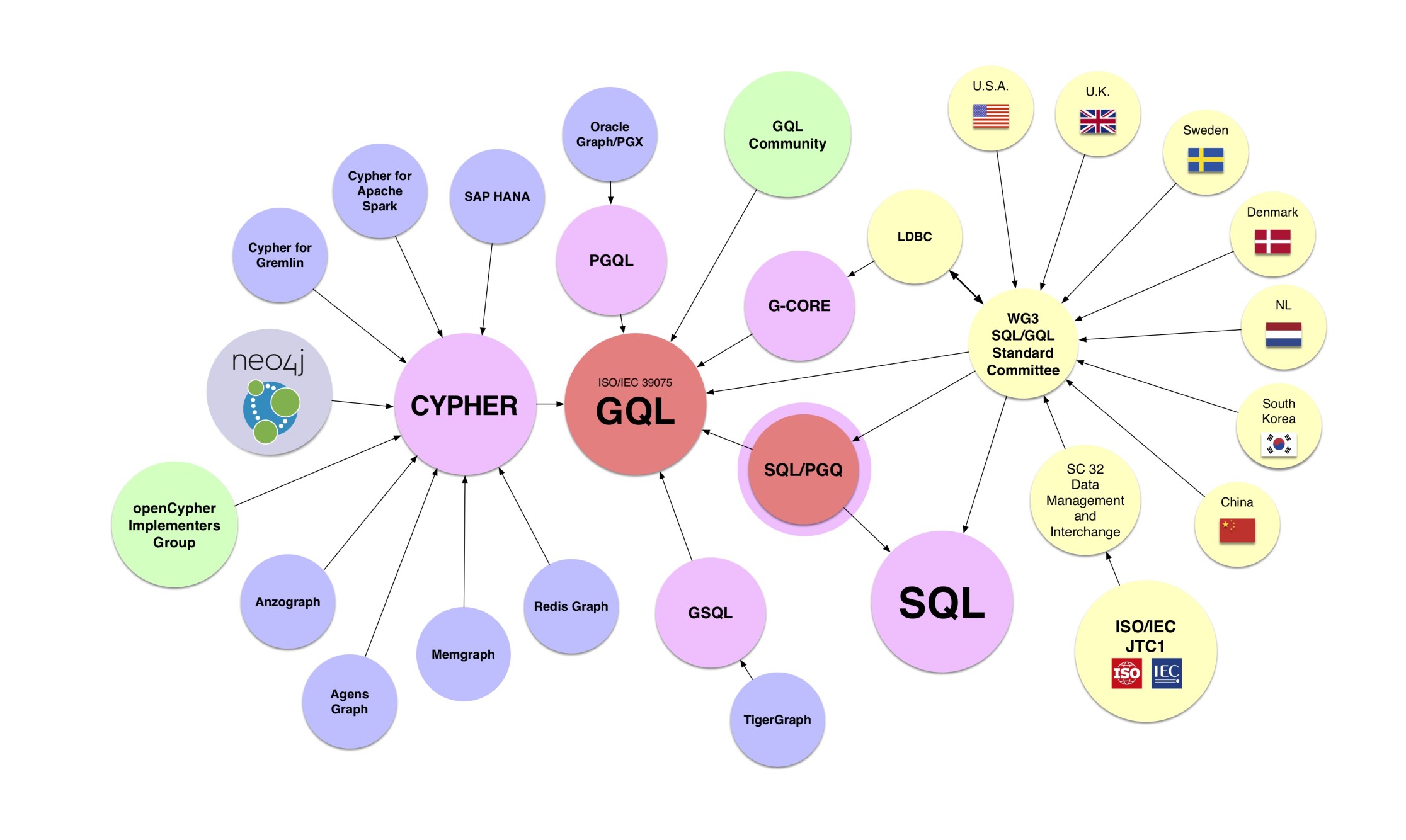
Only Japan voted against. Japan’s accompanying comments are interesting. They put forward two arguments: that existing languages out there already do the job, and specifically that SQL/Property Graph Query extensions in conjunction with the rest of the SQL standard can cover the ground.
I’d like to give my take on why the advocates of GQL were right to propose a new standard language alongside SQL.
Why we need a graph-specific query language
I put out the GQL Manifesto in May 2018. The proximate causes of that appeal were a) the fact that SQL/PGQ is restricted to read-only queries, b) that it cannot project new graphs, and c) that it can only access graphs that are based on taking a graph view over SQL tables.
But many vendors, researchers and users agree that graph databases can be developed using non-relational “graph native” storage and runtime models (like Neo4j’s industry-leading offering, or the new Redis Labs graph product). They most definitely want a language, like Cypher, that covers insertion and maintenance of data, and not just data querying. And SQL is unlikely to be the right model for a graph-centric language that can “compose over graphs” (i.e. takes graphs as query inputs and spit out a graph as a result, the same way SQL can read tables and form result sets which are new tables).
How GQL and SQL can work together
Many of the companies and national standards bodies that are backing the GQL initiative do not see GQL and SQL as competitors, covering the same ground, but as languages that can complement each other through shared foundations, and interoperation. (By foundations I mean core datatypes and ways of forming expressions, as well as shared concepts like schema objects held in catalogs, and user/role-associated sessions.)
Let’s look a bit further into how the two languages will interoperate.
A SQL/PGQ query is in fact a SQL sub-query wrapped around a chunk of “proto-GQL”. I’ve taken the liberty of showing below an example query from a very nice deck on SQL/PGQ which Oracle colleague Oskar van Rest produced for the July meeting of the Linked Data Benchmark Council in Amsterdam at the tail-end of this year’s SIGMOD.
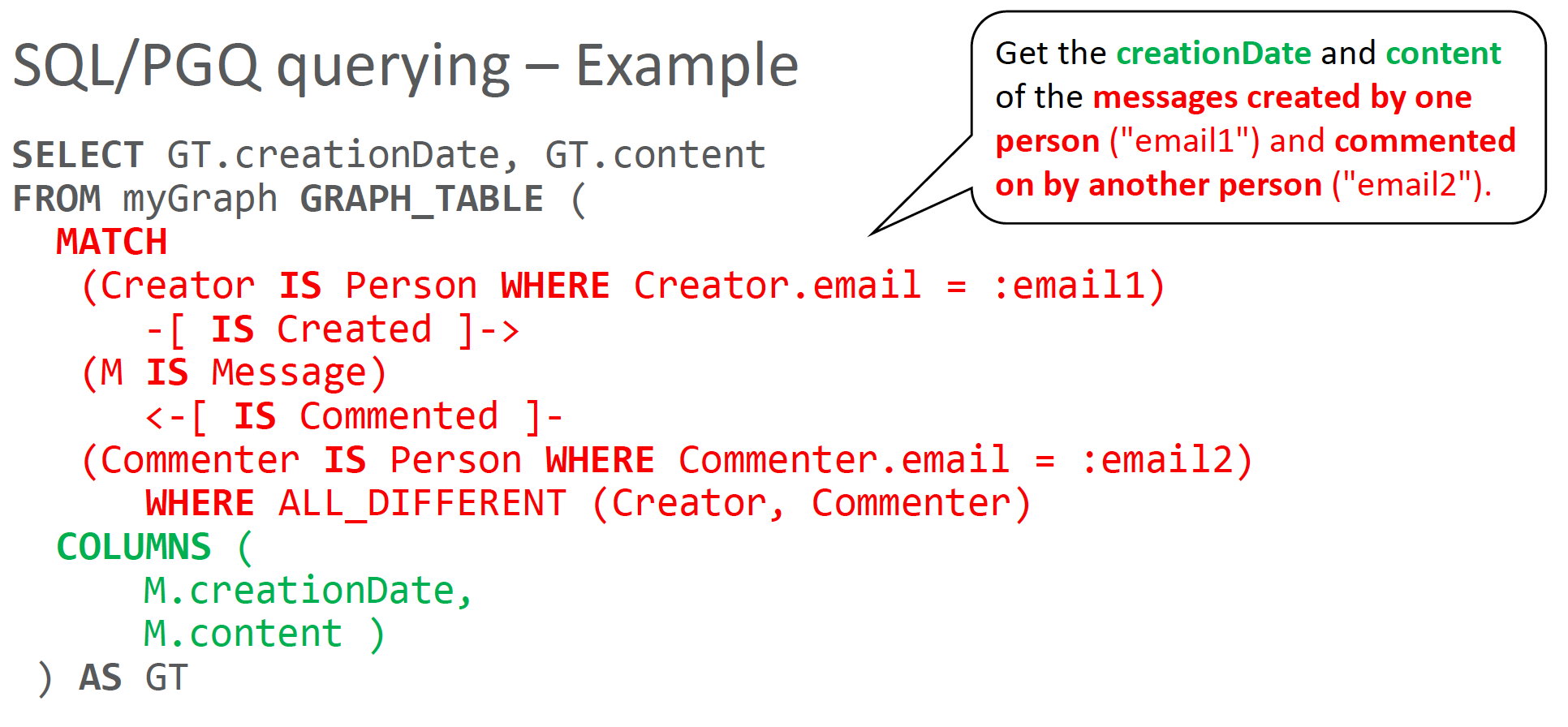
The part in red that starts with the keyword MATCH is a fragment of a pattern-matching query that is extremely close to one written in Cypher or PGQL (which are very similar languages in many ways). You may notice that IS is used to introduce a label (as in Creator IS Person), and that : is used to introduce a host-parameter or variable. But you could use colon in the label expression as well (if your SQL engine’s parser is smart enough) and then the similarity to the pre-existing “input” property graph query languages becomes even more marked.
The other parts of the PGQ query (in black and green) joint this proto-GQL into an SQL SELECT statement. Tabular results are flowed out via the COLUMNS clause into a regular SQL query. They are only interesting for SQL engines that are interacting with graph queries. GQL itself will not get involved in this kind of SQL “foreign function interface”.
SQL/PGQ: first stage of the GQL rocket
The pattern-matching read-only sublanguage (shown in red in Oskar’s sample query above) is destined to become an integral part of a full-CRUD GQL. It’s the “first stage of the GQL rocket”. That tight connection was part of the GQL project proposal document.
So one of the jobs of GQL is to codify things like the property graph data model and the use of labels as well as properties for query predicates: we get one standard way of doing things we can already do in existing languages. We want to go from many similar languages to one standard language.
But we also want to bring industrial innovations which vendors are working on into an enhanced, clear definition of the property graph database category. There are interesting new developments in SQL/PGQ like regular path queries, nested paths and path macros, all of which enhance the power of the popular pattern-matching paradigm. There are other innovations that GQL is going add which are not yet implemented by all vendors, but which are implemented at least in part by at least one vendor, and often by more than one.
Which brings us to the things SQL/PGQ can’t do, and is unlikely ever to be able to do.
SQL composes tables, GQL composes graphs
SQL is a language that is very different from Cypher in one critical respect. Cypher (and PGQ’s graph [“red”] sub-language) allows a user to explore the structure of her data graph without knowing up-front which types of data are going to be returned. They let you do a genuine graph query, where the interesting thing is not just the values, but the shape of a subset of the data, defined with respect to the values of elements that match a graph pattern. In other words, graph queries describe sub-graphs or projected graphs computed over one or more input graphs.
However, SQL/PGQ, or Cypher as you have it Neo4j today, and PGQL only let you extract a table from a graph. That’s a vital feature which must be preserved, because otherwise it’s not possible to get hold of actual data values stored on graph elements. But restricting results to tables means that you cannot easily create a chain of graph transformations, or carry out set operations over multiple input graphs. Nor can you generate and store snapshot graphs. Nor can you define graph-projecting views.
GQL will build on work in openCypher Morpheus, which brings Cypher to Apache Spark, and the inspiration of G-CORE from LDBC, to give users a composable graph query language, enabling all of those features. Which will make GQL into the conceptual equal of SQL … and then some.
I think that the SQL standards community has made the right decision here: allow SQL, a language built around tables, to quote GQL when the SQL user wants to find and project a table from a graph, but use GQL when the user wants to find and project a graph from a graph. Which means that we can produce and catalog graphs which are not just views over tables, but discrete complex data objects.
This relates to other graph features that SQL is not naturally fitted to.
Graph patterns for CRUD
DML to insert, update and delete graphs (and paths, and elements) is very closely related to the DQL used to match and extract data. Better therefore to use a shared pattern-centric vocabulary in both operations. Which means that GQL is the right (single) place to add the “CUD” to PGQ’s “R”.
You could update tables under graph views to achieve the same effects (if and only if you are in a graph-equipped SQL engine) but that takes you away from the simplicity and power of the graph data model. It would be like writing to a SQL view by writing updates on all the base tables: possible but self-defeating.
SQL quoting GQL
As GQL adds data modification on top of the work done in SQL/PGQ we create an “even more quotable” GQL. If a SQL user wants to push data from the tabular database into graph objects stored in a database catalog then the natural thing to do is quote even more GQL to perform that graph-specific job inside a SQL GRAPH_MODIFY function.
When we in Neo4j first mooted “SQL quotes Cypher” in the standards discussions on PGQ, back in 2017, the comment came back that “Cypher isn’t a referenceable international standard”. Which leads us straight to GQL. It will be an official international standard, and it can be quoted by SQL. And of course, over time (like you can do in Morpheus) we may want to allow GQL to quote some SQL for table operations!
Property graph schema
Which brings us to another major piece of functionality that SQL is unsuited to. The type of a graph is the types of its nodes, plus the types of its edges and the types of nodes that they can join. Nodes and relationships of a particular type store data values: labels and properties (content) of a particular type.
SQL does not have an evolved concept of expressing complex types by type composition and parameterization. And the most natural way of expressing the type of a graph is by showing the patterns of data relationships that it encodes. Enter property graph types defined using “record types” for the content (the labels and properties) of elements, and patterns for composing those content types into nodes and relationships, including direction.
The image below is a Neo4j proposal that has not been agreed by the working groups who have been preparing for the GQL project, but it certainly gives an idea of how succinct and expressive patterns in ASCII line art can help to document and visualize a graph and its type.
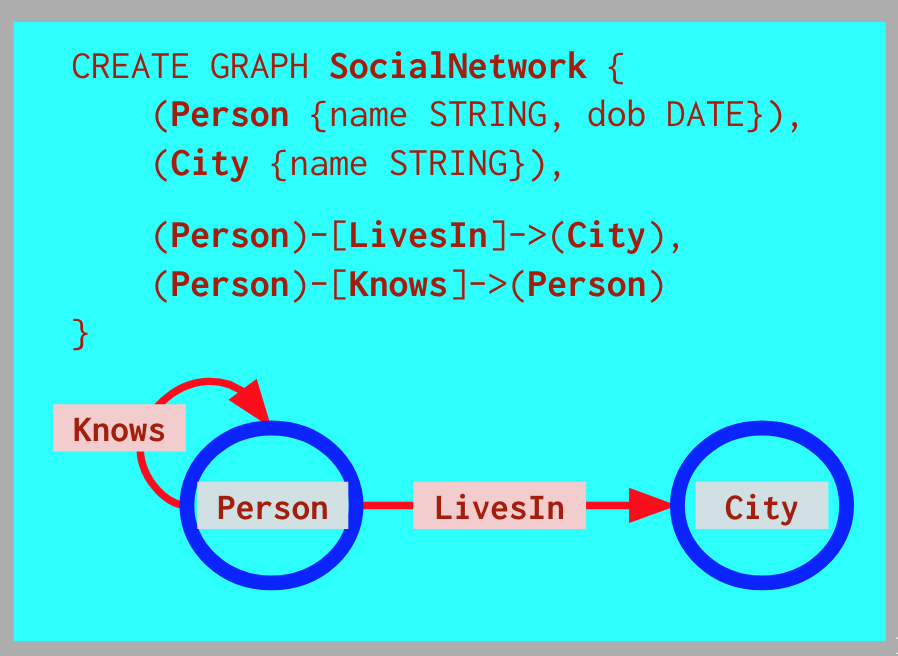
Incidentally, GQL is likely to codify schema, querying and modification of undirected relationships (a feature already present in PGQL and Tigergraph’s GSQL). More generally, GQL is an opportunity to arrive at a more modern language than SQL, with a more structured type system, and clean composition of queries viewed as procedures, with parameters (allowing parameterized views) and both forward (linear) and nested procedure composition.
“Omnigraphs”
I have saved for last one of the most interesting ways in which GQL takes us to a different place than SQL. In the G-CORE research language, you can take the union of two graphs and then add new elements (nodes and relationships) to create a third graph. The authors think in terms of “constructing on” existing graphs. G-CORE (like Cypher for Apache Spark) operates only over immutable data, so the third graph, in this approach, is in fact a copy of the first two, plus any new data.
But databases are mutable stores. In Neo4j we’ve started calling the mutable equivalent of this “two plus new” design pattern an omnigraph. It’s a combination of a view and a base graph, and there is no equivalent in SQL, because SQL does not structure data with any explicit relationships, but only has value-mediated links (foreign keys).
A GQL view, like a SQL view, will allow you to see data that results from a function over base tables. Any update on that view will write through to the base tables. A GQL base graph, like a SQL base table, will allow you to store and read data directly. But a GQL “omnigraph” would be a graph where some of the data is derived through views over other graphs (including other views), and some of the data is new and unique to the graph concerned (is base data). This gives the possibility of adding relationships between elements in pre-existing graphs, but these relationships only exist in the “overlay” omnigraph.
Such an arrangement is like a named union of base and derived tables in SQL, which are grouped together because of the intrinsic graph that their foreign key and link table relationships form. We feel that it is more natural to call this particular duck … a graph, and define and query it using a Graph Query Language.
WG3 meeting soon in Arusha, Tanzania
The work of the GQL project starts in earnest at the next meeting of the SQL/GQL standards committee, ISO/IEC JTC 1 SC 32/WG3, in Arusha, Tanzania, later this month.
It is impossible at this stage to say when the first implementable version of GQL will become available, but it is highly likely that some reasonably complete draft will have been created by the second half of 2020.
GQL Community Update 9 October
On Wednesday 9 October, a GQL Community Update web-conference is being held, co-chaired by Peter Boncz, chair of the LDBC, and Keith Hare, convenor of WG3.
This meeting will discuss different topics and workstreams, including community efforts organized in two LDBC “task forces” for property graph schema and existing languages analysis. This follows the decision by LDBC’s board of directors to act as the organizing centre for community efforts to support GQL, taking advantage of LDBC’s formal liaison with WG3.
Ideas are brewing about using formal denotational semantics to assist the quality and exactness of the GQL specification, building on similar work in Edinburgh and Warsaw to define formal semantics for parts of Cypher (including the interesting Cypher.PL executable semantics project, written in Prolog). It is also highly likely, as time progresses, that open-source software for grammar tooling and for conformance testing will begin to be created to support the official specification, in the style of the openCypher project.
Defining the category of property graph data management
There’s a lot more heavy thinking, writing and editing to come, building on strong beginnings, but GQL has the potential to become the defining standard for property graphs: one of the most exciting and powerful categories of data management to have taken root industrially in this century.
To contact me please connect or message via LinkedIn in the first instance, or mail querylanguages@neo4j.com.